69 lines
2.7 KiB
Markdown
69 lines
2.7 KiB
Markdown
---
|
||
title: 处理器大小端存储模式
|
||
tags:
|
||
- 大小端存储
|
||
categories:
|
||
- c语言
|
||
abbrlink: c25386f8
|
||
date: 2017-09-13 17:01:49
|
||
---
|
||
大端模式:是指数据的**高字节**保存在内存的**低地址**中,而数据的**低字节**保存在内存的**高地址**中。
|
||
|
||
小端模式:是指数据的**高字节**保存在内存的**高地址**中,而数据的**低字节**保存在内存的**低地址**中。
|
||
|
||
例如:一个数据无符号32位整数0x12345678,其中0x12属于高字节(权值大)而0x78属于低字节(权值小),在不同的模式下存储的方式如下表:
|
||
|
||
内存地址 | 0x1000 | 0x1001 | 0x1002 | 0x1003 |
|
||
--- | --- | --- | --- | --- |
|
||
大端模式 | 0x12 | 0x34 | 0x56 | 0x78 |
|
||
小端模式 | 0x78 | 0x56 | 0x34 | 0x12 |
|
||
|
||
我们可以看得出来大端模式和我们的阅读习惯相同,权值从左往右是高位->低位而地址则是低位->高位。小端模式则是随着地址从左往右增大权值增大。地址就代表了权值的大小。
|
||
|
||
<!---more---->
|
||
|
||
利用下面c代码可以看到运行环境是如何存储一个uint数据的。
|
||
|
||
```c
|
||
#include <stdio.h>
|
||
int endian(void);
|
||
int main(int argc,char arg[])
|
||
{
|
||
unsigned int a=0x12345678;
|
||
char *ap=&a;
|
||
int i=0;
|
||
printf("0x%x storage in system is:\r\n",a);
|
||
for(i=0;i<4;i++)
|
||
printf("addr:0x%x,value:0x%x\r\n",ap+i,ap[i]);
|
||
printf("system storage by %s_endian",endian()? "Big":"Little");
|
||
return 0;
|
||
}
|
||
```
|
||
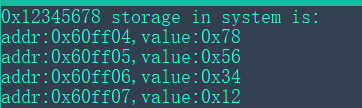
运行的结果如下,可以看出该系统是小端系统。
|
||
|
||
[](https://imgchr.com/i/1Mp4A)
|
||
|
||
我们如何简单的判断一个系统的大小端呢。我们知道**共用体(联合体)**存储在内存里是共用一块地址的,其占用空间决定于最大成员所需的空间,他们的起始地址相同。所以我们可以利用一个共用体,成员分别是一个int和一个char。通过给int赋值1,然后检测char对应的值是多少,如果是1代表系统将数据1放到了int的起始地址(因为char是一个字节必然在起始地址)。而起始地址是低地址,低地址存放的1(权值小)推出该系统是小端系统。否则该系统是大端系统。
|
||
|
||
C代码如下
|
||
```C
|
||
int endian()
|
||
{
|
||
union{
|
||
int a;
|
||
char b;
|
||
}endunion;
|
||
endunion.a=1;
|
||
if(endunion.b==1)//如果成员b是1则证明随地址顺序和数字权值顺序相同是小端模式
|
||
return 0;//小端
|
||
return 1;//大端
|
||
}
|
||
```
|
||
还可以用一个更加简洁的办法(原理都是检测int的起始地址存放的是什么值),代码如下
|
||
```C
|
||
int endian()
|
||
{
|
||
int a=1;
|
||
return !(*((char *)&a));//取a的地址,将其强制转化为char指针,然后取出该地址存放的值并取反;
|
||
}
|
||
``` |