124 lines
4.4 KiB
Markdown
124 lines
4.4 KiB
Markdown
|
|
---
|
|||
|
|
title: 测试编译器是否支持嵌套注释
|
|||
|
|
date: 2017-10.1 00:16:47
|
|||
|
|
tags:
|
|||
|
|
- 嵌套注释
|
|||
|
|
categories:
|
|||
|
|
- c语言
|
|||
|
|
abbrlink: a56a64b5
|
|||
|
|
---
|
|||
|
|
|
|||
|
|
问题:某些C编译器允许嵌套注释。请写一个测试程序,要求:无论是对允许嵌套注释的编译器,还是对不允许嵌套注释的编译器,该程序都能正常通过编译(无错误消息出现), 但是这两种情况下程序执行的结果却不相同。
|
|||
|
|
|
|||
|
|
提示: 在用双引号括起的字符串中, 注释符 /* 属于字符串的一部分,而在注释中出现的双引号 " " 又属于注释的一部分。
|
|||
|
|
|
|||
|
|
出自——《C陷阱与缺陷》练习1-1
|
|||
|
|
|
|||
|
|
<!---more---->
|
|||
|
|
|
|||
|
|
嵌套注释:顾名思义就是注释里嵌套着注释。比如
|
|||
|
|
```C
|
|||
|
|
/*"/*"*/"*/
|
|||
|
|
```
|
|||
|
|
对于这段代码,不同的编译器识别的结果不同:
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
|
|||
|
|
我们如何通过代码的输出判定编译器是否支持嵌套注释呢,重点就是让同一段代码,支持嵌套注释的编译器和不支持嵌套注释的编译器注释掉不同的地方。根据题目的提示字符串中的 /\* 是属于字符串的一部分,比如 "/\*aa\*/" 这里面的注释标号编译器是不会理会的,而 /\*"aa\*"/ 这里面的 "aa" 是不会识别为字符串的。还有一点无论是 " " 还是 /\*\*/都是就近匹配的。
|
|||
|
|
|
|||
|
|
|
|||
|
|
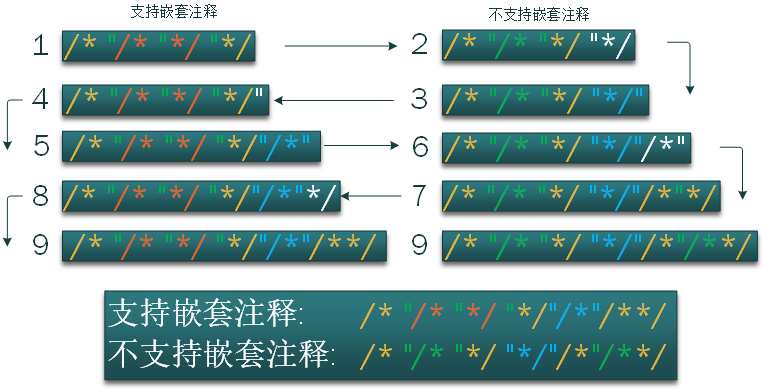
- 1. 我们首先构建一个嵌套的注释,这个注释在**支持**嵌套注释的编译器里能编译通过,而在**不支持**的编译器里编译失败:
|
|||
|
|
```C
|
|||
|
|
/*"/*"*/"*/
|
|||
|
|
```
|
|||
|
|
不支持的系统中出现了"\*/"导致编译失败
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
|
|||
|
|
- 2. 我们通过添加一个 " 使得不支持的系统编译成功
|
|||
|
|
```C
|
|||
|
|
/*"/*"*/"*/"
|
|||
|
|
```
|
|||
|
|

|
|||
|
|
|
|||
|
|
|
|||
|
|
- 3. 可以看出这样添加之后不支持的编译器已经能编译成功并且有输出一字符串,支持的系统由于多了一个 " 导致编译失败,根据题目提示我们构建一个字符串" "并且"/\*,\*/" 两两配对,所以我们添加一个 /\*形成"/\*"
|
|||
|
|
```C
|
|||
|
|
/*"/*"*/"*/"/*"
|
|||
|
|
```
|
|||
|
|

|
|||
|
|
|
|||
|
|
|
|||
|
|
- 4. 这样操作之后支持/不支持的编译器输出不同的字符串(蓝色部分),但是不支持的编译器多了 /\* "编译失败,而它刚好又是多行注释的头,所以我们得加一个尾 \*/ 使得他们配对。
|
|||
|
|
```C
|
|||
|
|
/*"/*"*/"*/"/*"*/
|
|||
|
|
```
|
|||
|
|

|
|||
|
|
|
|||
|
|
|
|||
|
|
- 5. 我们从上图可以看出不支持嵌套注释的编译器已经能通过编译并且有区别去支持嵌套注释的编译器的输出。但是支持嵌套注释的编译器由于多了\*/导致编译失败,因为不支持嵌套注释的编译器的注释之间无论是什么都可以忽略,所以我们在最后的 \*/ 之前加一个 /\* 让支持嵌套注释的编译器能找到配对的注释对。
|
|||
|
|
```C
|
|||
|
|
/*"/*"*/"*/"/*"/**/
|
|||
|
|
```
|
|||
|
|

|
|||
|
|
|
|||
|
|
|
|||
|
|
通过上述步骤我们找到了一个合适的语句使得在两种编译器中编译成功并且有不同的输出。
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
通过一段简单的代码我们可以看下效果
|
|||
|
|
|
|||
|
|
```c
|
|||
|
|
#include <stdio.h>
|
|||
|
|
int ISSupNestComment(void);
|
|||
|
|
int main()
|
|||
|
|
{
|
|||
|
|
printf("This compiler %s support nested comment \r\n",
|
|||
|
|
ISSupNestComment()? "": "does not");
|
|||
|
|
return 0;
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
int ISSupNestComment()
|
|||
|
|
{
|
|||
|
|
char *Str=/*"/*"*/"*/"/*"/**/;
|
|||
|
|
if(Str[0]=='*')//"*/"不支持嵌套注释
|
|||
|
|
return 0;
|
|||
|
|
else //"/*"支持嵌套注释
|
|||
|
|
return 1;
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
|
|||
|
|
自己做完这个感觉还是有点意思的,上网搜了一波,发现别人想的更是精妙。不禁发出一套赞赏三连,卧槽牛逼666。下面我们看下一大佬们是怎么做的。
|
|||
|
|
|
|||
|
|
# 1.Doug McIlroy
|
|||
|
|
```C
|
|||
|
|
/*/*/0*/**/1
|
|||
|
|
```
|
|||
|
|
这个解法主要利用了编译器作词法分析时的“大嘴法”规则。编译器支持嵌套注释,则上式将被解释为**1**.编译器不支持嵌套注释,则上式将被解释为 **0\*1**.
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
# 2.[TimWu](http://www.cppblog.com/Tim/archive/2011/03/25/142726.html)
|
|||
|
|
|
|||
|
|
```c
|
|||
|
|
#define A /* aaa /* a*/ a
|
|||
|
|
#define B */
|
|||
|
|
|
|||
|
|
bool CanNesting()
|
|||
|
|
{
|
|||
|
|
#ifdef B
|
|||
|
|
return false;
|
|||
|
|
#else
|
|||
|
|
return true;
|
|||
|
|
#endif
|
|||
|
|
}
|
|||
|
|
```
|
|||
|
|
他利用的多行注释和宏定义的特性,编译器支持嵌套注释宏定义B则会被注释掉导致没有宏定义B。编译器不支持嵌套注释,宏定义B则会定义为 \*/。通过预编译判断就可以输出结果。
|
|||
|
|
|
|||
|
|

|